
Всем привет! Сегодня я бы хотел Вам рассказать про файл robots.txt. Да, про него очень много чего написано в интернете, но, если честно, я сам очень долгое время не мог понять, как же создать правильный robots.txt. В итоге я сделал один и он стоит на всех моих блогах. Проблем с индексацией сайта я не замечаю, robots.txt работает просто великолепно.
Robots.txt для WordPress
А зачем, собственно говоря, нужен robots.txt? Ответ все тот же – продвижение сайта в поисковых системах. То есть составление robots.txt – это одно из частей поисковой оптимизации сайта (кстати, очень скоро будет урок, который будет посвящен всей внутренней оптимизации сайта на WordPress. Поэтому не забудьте подписаться на RSS, чтобы не пропустить интересные материалы.).
Одна из функций данного файла – запрет индексации ненужных страниц сайта. Также в нем задается адрес карты сайта sitemap.xml и прописывается главное зеркало сайта (сайт с www или без www).
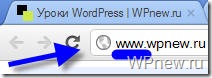
Примечание: для поисковых систем один и тот же сайт с www и без www совсем абсолютно разные сайты. Но, поняв, что содержимое этих сайтов одинаковое, поисковики “склеивают” их. Поэтому важно прописать главное зеркало сайта в robots.txt. Чтобы узнать, какое главное (с www или без www), просто наберите адрес своего сайта в браузере, к примеру, с www, если Вас автоматически перебросит на тот же сайт без www, значит главное зеркало Вашего сайта без www. Надеюсь правильно объяснил.
Было:
Стало (после перехода на сайт, www автоматически удалились, и сайт стал без www):
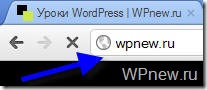
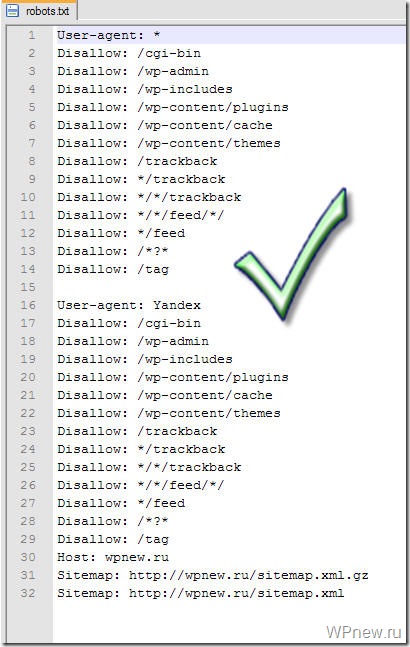
Так вот, этот заветный, по-моему, правильный robots.txt для WordPress Вы можете увидеть ниже.
Правильный Robots.txt для WordPress
User-agent: *
Disallow: /cgi-bin
Disallow: /wp-admin
Disallow: /wp-includes
Disallow: /wp-content/plugins
Disallow: /wp-content/cache
Disallow: /wp-content/themes
Disallow: /trackback
Disallow: */trackback
Disallow: */*/trackback
Disallow: */*/feed/*/
Disallow: */feed
Disallow: /*?*
Disallow: /tag
User-agent: Yandex
Disallow: /cgi-bin
Disallow: /wp-admin
Disallow: /wp-includes
Disallow: /wp-content/plugins
Disallow: /wp-content/cache
Disallow: /wp-content/themes
Disallow: /trackback
Disallow: */trackback
Disallow: */*/trackback
Disallow: */*/feed/*/
Disallow: */feed
Disallow: /*?*
Disallow: /tag
Host: wpnew.ru
Sitemap: https://wpnew.ru/sitemap.xml.gz
Sitemap: https://wpnew.ru/sitemap.xml
Все что дано выше, Вам нужно скопировать в текстовой документ с расширением .txt, то есть, чтобы название файла было robots.txt. Данный текстовой документ Вы можете создать, к примеру, с помощью программы Notepad++. Только, не забудьте, пожалуйста, изменить в последних трех строчках адрес wpnew.ru на адрес своего сайта. Файл robots.txt должен располагаться в корне блога, то есть в той же папке, где находятся папки wp-content, wp-admin и др. .
Те, кому же лень создавать данный текстовой файл, можете просто скачать robots.txt и также там подкорректировать 3 строчки.
Хочу отметить, что в техническими частями, о которых речь пойдет ниже, себя сильно загружать не нужно. Привожу их для “знаний”, так сказать общего кругозора, чтобы знали, что и зачем нужно.
Итак, строка:
User-agent
задает правила для какого-то поисковика: к примеру “*” (звездочкой) отмечено, что правила для всех поисковиков, а то, что ниже
User-agent: Yandex
означает, что данные правила только для Яндекса.
Disallow
Здесь же Вы “засовываете” разделы, которые НЕ нужно индексировать поисковикам. К примеру, на странице https://wpnew.ru/tag/seo у меня идет дубль статей (повторение) с обычными статьями, а дублирование страниц отрицательно сказывается на поисковом продвижении, поэтому, крайне желательно, данные секторы нужно закрыть от индексации, что мы и делаем с помощью этого правила:
Disallow: /tag
Так вот, в том robots.txt, который дан выше, от индексации закрыты почти все ненужные разделы сайта на WordPress, то есть просто оставьте все как есть.
Host
Здесь мы задаем главное зеркало сайта, о котором я рассказывал чуть выше.
Sitemap
В последних двух строчках мы задаем адрес до двух карт сайта, созданные с помощью плагина Google XML Sitemaps.
Возможные проблемы
Если у Вас на блоге не стоит ЧПУ (именно так у меня происходит с тем сайтом, которого я занимаюсь продвижением), то с тем robots.txt, который дан выше, могут быть проблемы. Напомню, что без ЧПУ ссылки на сайте на посты выглядят примерно следующим образом:
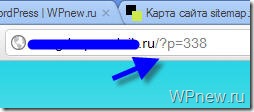
А вот из-за этой строчки в robots.txt, у меня перестали индексироваться посты сайта:
Disallow: /*?*
Как видите, эта самая строка в robots.txt запрещает индексирование статей, что естественно нам нисколько не нужно. Чтобы исправить это, просто нужно удалить эти 2 строчки (в правилах для всех поисковиков и для Яндекса) и окончательный правильный robots.txt для WordPress сайта без ЧПУ будет выглядеть следующим образом:
User-agent: *
Disallow: /cgi-bin
Disallow: /wp-admin
Disallow: /wp-includes
Disallow: /wp-content/plugins
Disallow: /wp-content/cache
Disallow: /wp-content/themes
Disallow: /trackback
Disallow: */trackback
Disallow: */*/trackback
Disallow: */*/feed/*/
Disallow: */feed
Disallow: /tag
User-agent: Yandex
Disallow: /cgi-bin
Disallow: /wp-admin
Disallow: /wp-includes
Disallow: /wp-content/plugins
Disallow: /wp-content/cache
Disallow: /wp-content/themes
Disallow: /trackback
Disallow: */trackback
Disallow: */*/trackback
Disallow: */*/feed/*/
Disallow: */feed
Disallow: /tag
Host: wpnew.ru
Sitemap: https://wpnew.ru/sitemap.xml.gz
Sitemap: https://wpnew.ru/sitemap.xml
Анализ robots.txt
Чтобы проверить, правильно ли мы составили файл robots.txt я рекомендую Вам воспользоваться сервисом Яндекс Вебмастер (как регистрироваться в данном сервисе я рассказывал тут).
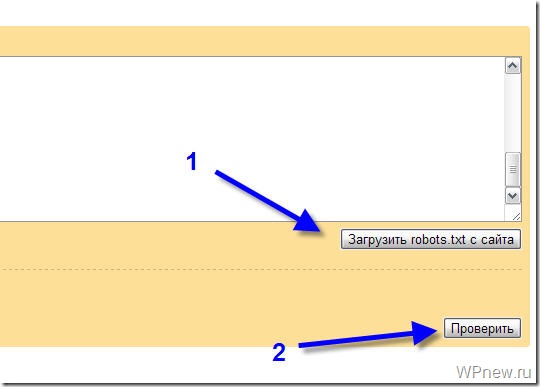
Заходим в раздел Настройки индексирования –> Анализ robots.txt:
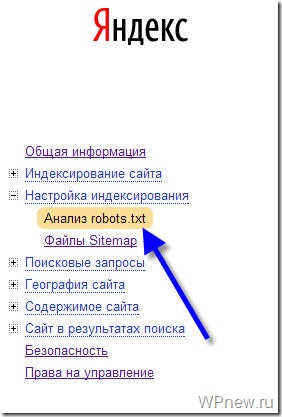
Уже там нажимаете на кнопку “Загрузить robots.txt с сайта”, а затем нажимаете на кнопку “Проверить”:
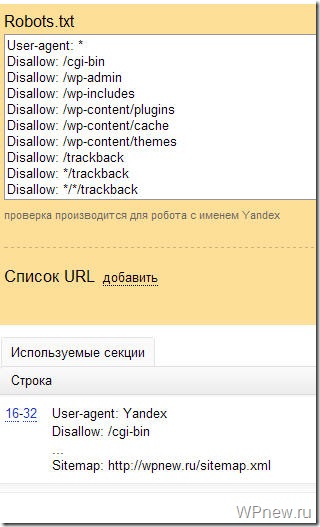
Если Вы увидите примерно следующее сообщение, значит у Вас правильный robots.txt для Яндекса:
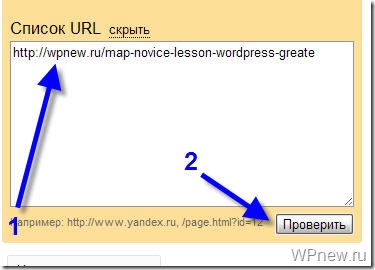
Также Вы можете в “Список URL” добавить адрес любой статьи сайта, чтобы проверить не запрещает ли robots.txt индексирование данной страницы:
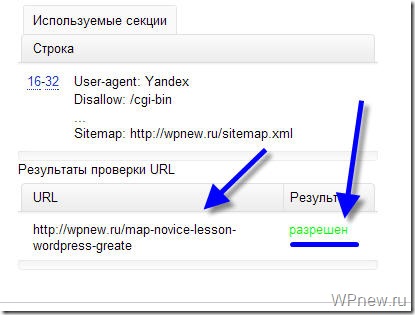
Как видите, никакого запрета на индексирование страницы со стороны robots.txt мы не видим, значит все в порядке :).
Надеюсь больше вопросов, типа: как составить robots.txt или как сделать правильным данный файл у Вас не возникнет. В этом уроке я постарался показать Вам правильный пример robots.txt:
Вы можете посмотреть другие варианты, как еще можно составлять robots.txt.
До скорой встречи!
P.s. Совсем недавно я добавил блог в Яндекс Каталог, что же интересного произошло? 🙂




Еще хотел бы добавить, в некоторых темах на wp, появляются ненужные ссылки. У меня была такая — /?printf=1 (печать записи), яндекс нашел к ней ссылки и проиндексировал — в итоге дублированный контент. Я удалил в теме ссылку, ой так о чем же я говорю, у нас же темы одинаковые. У тебя тоже может быть эта ссылка. В общем, я запретил в роботсе еще и /?print
По-моему, вы уже об этом писали, Петр!
Я просто давал robots.txt. А здесь постарался разъяснить что к чему.
Привет Петер 🙂 Тут для меня америка не открылась, но вспомнился вопрос касаемо тех самых дублирующихся статей. Хотелось бы поболее инфы получить именно об этом. Почему такое пишу: у меня на сайте немало вхождений с ПС именно с тегов (то есть ПС выдают страницу какого-либо тега «сайт/tag/название тега»). Сегодня попробую закрыть всё, посмотрю как скажется на посещениях.
у меня непонятная проблема с этим файлом..да и не у одного меня
в индексе гугла пару тысяч страниц (сейчас 5080, а было более 7к, при том, что их должно быть около 300)
прикол в чем: переходим сюда
http://www.google.com/search?&q=site:http://sidash.ru
Результатов: примерно 6 140
потом идем на последнюю страницу в поисковике
http://www.google.com/search?&q=site:http://sidash.ru#q=site:http://sidash.ru&hl=ru&prmd=imvns&ei=b8qMTuCECamw0AWys4DpBQ&start=380&sa=N&bav=on.2,or.r_gc.r_pw.r_cp.,cf.osb&fp=703b5ce7af564065&biw=1366&bih=643
и видим
Результатов: 331
я уже и в гугл писал, чтобы сделали перерасчет страниц.. прошло пару недель, а в индексе стало лишь на 1 тысячу страниц меньше
мою проблему никто не знает как решить?
К сожалению, я нет…
Уважаемый sidash!
1 вариант который вы привели — это просто поисковый запрос,
2 вариант более конкретизированный, и показывает только результаты по сайту
На одном из сайтов проситал, что нужно запретить индексацию Yahoo.
Как Ваше мнение, нужно это сделать или нет?
А зачем собственно говоря это нужно? (как было там написано?), Если честно, я первый раз об этом слышу.
я не совсем разобрался, но, как я понял, Yahoo
практически не дает трафика в рунете, но при этом показывает все ссылки входящие.
Следовательно конкуренты могут видеть какие сайты ссылаются и, следовательно, каким-то образом это использовать 🙂
Ой, я по этому поводу не запариваюсь 🙂 Конкуренты, если нужно, и без Yahoo справятся :).