
Привет. В прошлый раз я начал вам показывать, как составить семантическое ядро сайта на примере интернет магазина. Сегодня продолжение, вторая часть.
Итак, в прошлый раз с помощью Базы Пастухова мы собрали все требуемые нам ключевые слова. Если же у вас нет этой самой Базы Пастухова (эту ситуацию можно понять, данный софт очень дорогой), мы парсим ключевые слова с Яндекс Вордстата. Давайте я распишу все пошагово.
Key Collector
- В программе Key Collector нажимаем на кнопку «Пакетный сбор из левой колонки Яндекс Вордстат» (если вы работали с Базой Пастухова, то просто загружаете в Кей Коллектор собранные «ключи»):

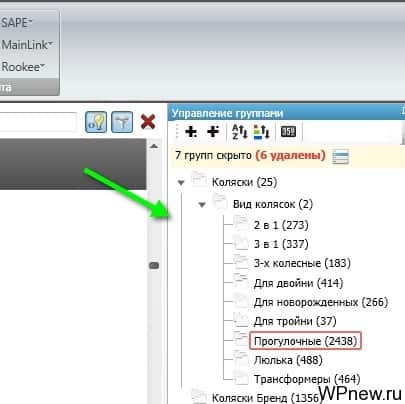
- В одну вкладку (группу) собираем ключевые слова из созданной нами структуры сайта. В моем случае это может быть, например, все фразы, которые содержат «коляски прогулочные».
- Также можете воспользоваться сбором поисковых подсказок, аналогично добавятся еще ключевые слова. Я вообще первые три пункта пропускаю, так как повторюсь, ключевые слова собрал уже в Базе Пастухова. А вот кнопка сбора поисковых подсказок:

- Снова раскидываем все по подгруппам, соблюдая иерархию. То есть, в моем случае получается что-то вроде этого:

- Дальше собираем частотность по требуемому региону. Собирать частотность в Key Collector можно двумя инструментами:

- Я вам настоятельно рекомендую пользоваться инструментом, которая отмечена на скриншоте выше, как цифра «2», то есть через Яндекс Директ. Вы сэкономите часы (!) своего времени. Как правильно настроить сбор частотности, изучите в официальной справке программы Key Collector.
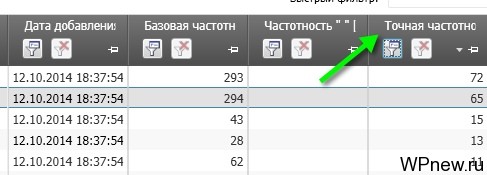
- Дальше я удаляю «запросы-пустышки». То есть я собираю точную частотность («Частотность «!» Яндекс Вордстат») и те запросы, которые меньше определенного количества, я удаляю. Если клиент требует низкочастотники или даже микроНЧ, я их, конечно оставляю. Если же вам они не нужно, то, что меньше 10-20 точной частотности, можно смело удалять. Ну, если вы сомневаетесь, какие запросы удалять, для начала просто удалите «нулевики», то есть те запросы, у которых точная частотность равна 0. А дальше будете ориентироваться уже по требуемому объему ключевых слов (точная частотность — это количество запросов данного ключевого слов в точном вхождении (с учетом падежа) за месяц):

- Не обращайте внимание на название столбцов, он у вас скорей всего называется, как «Частотность «!» Яндекс Вордстат». Любой столбец можно переименовать для удобства в настройках. Удалив «запросы-пустышки», количество ненужных ключевых фраз серьезно уменьшается.
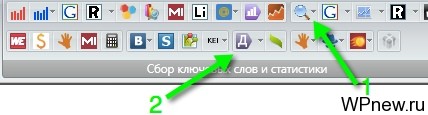
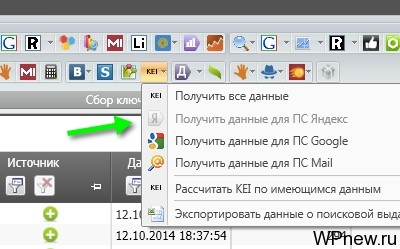
- Так как приходится ждать работу Key Collector (все зависит от размахов проекта), я стараюсь делать все, чтобы он не «простаивал» просто так без дела. Дальше я собираю данные конкурентности запросов (я ориентируюсь на Яндекс). Для этого нажимаю на кнопку «KEI» -> «Получить данные для ПС Яндекс»:

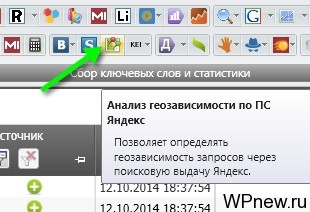
- Пока программа собирает данные, полезно бывает в некоторых случаях запустить определение геозависимости запросов. Мы прекрасно знаем, что, например, информационным сайтам очень тяжело выйти в ТОП по геозависимым запросам, они рассчитаны для коммерческих сайтов (что такое геозависимые и геонезависимые запросы?):

- Параллельно вы можете запустить сбор других данных для требуемого проекта. В большинство случаев для меня и клиентов достаточно знать точную частотность запроса и его конкуренцию. После того, как у меня завершится сбор данных конкуренции для Яндекса (см. пункт №8), я подсчитываю так называемые KEI:

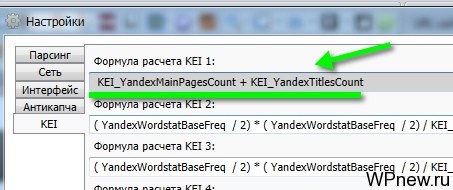
- Что такое KEI? Это некая величина, которая состоит из сложений разных величин. То есть мы сами можем задать формулу подсчета конкуренции. Я считаю конкуренцию по этой формуле: KEI_YandexMainPagesCount + KEI_YandexTitlesCount. Задается формула в настройках:

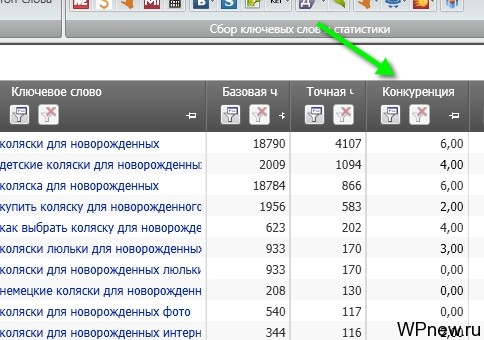
- По этой формуле наша конкуренция — это сумма количества сайтов, содержащих ключевые слова в Title главной страницы + количество сайтов, у которых в Title содержится ключевые слова на внутренних страницах. Причем анализируется только ТОП-10. То есть, например, фраза «шерстяные носки». Смотрим выдачу Яндекса (первые ТОП-10):

- Аналазируется первые 10 результатов. На скриншоте выше видно, что третий сайт не содержит в Title фразу «шерстяные носки», соответственно, он не будет считаться при подсчете KEI. То есть, допустим по данному запросу 8 сайтов содержат фразу в TItle на внутренней странице, 1 сайт в Title главной страницы, а 1 сайт вообще не содержит. Соответственно, формула посчитает 8+1=9. KEI 1, которая будет в столбце, это и будет наш показатель конкурентности, то есть максимальное значение данной цифры может быть = 10. Иногда бывает, что и все 12 показывает Key Collector, это небольшой сбой, в таких случаях вручную потом после экспорта прописываем цифру 10. То есть те запросы, которые содержат цифру 10 в столбце KEI 1 (в случае с моей формулой) получается наиболее конкурентные запросы.

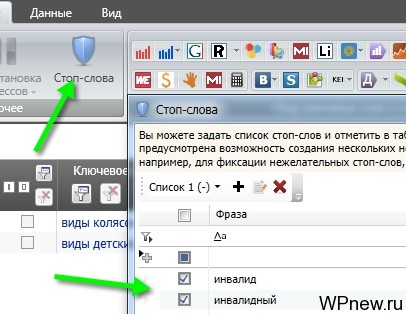
- Дальше вам нужно удалить ненужные «мусорные» ключевые слова. Например, так как я собираю семантическое ядро к детским коляскам, часто проскакивают фразы, связанные с инвалидными колясками. Поэтому, для подобных случаев используем «Стоп-слова», я просто вбил фразы «инвалид», «инвалидный» (причем не нужно «париться» со склонениями) и сразу же в таблице отмечаются те ключевые слова, которые содержат данные фразы. Потом просто нажимаем на таблицу правой кнопкой мыши и «Удалить отмеченное».

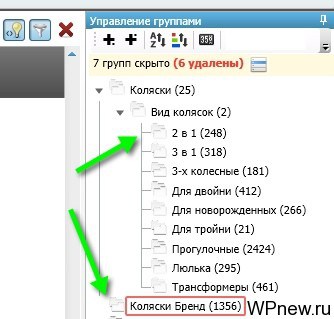
- Помимо всего это бывают такие фразы, которые содержатся в нескольких вкладках. Например: «коляска tako 2 в 1». Это ключевое слово можно отнести и к группе «2 в 1» и в тоже время в группу с брендами:

- В таких случаях нужно рассуждать логически и понять, куда лучше отнести фразу. В моем случае, человек ищет коляску именно фирмы «tako», то есть название бренда более уточняющее слово во всей фразе. Поэтому все запросы, которые содержат бренды, я осталяю только в группе «коляски бренд», а в других группах убираю. Для этого просто загрузил в «Стоп-слова» список брендов и удаляю фразы, содержие их на всех вкладках, кроме «Коляски Бренд».
- Даже после всевозможных фильтраций, не жалейте свое время, пройдитесь по спискам запросов, почистите мусор «ручками». Полностью автоматически все ненужные ключевые слова удалить просто невозможно.


И, ребята, если еще кто не в курсе: во время активной работы в Key Collector будут выскакивать капчи от поисковых систем. Я вас умоляю, не тратьте свои нервы и время, зарегистрируйтесь в сервисе Antigate, пополните счет на какие-нибудь 3$. Они вам хватят чуть ли не на полгода. И вам не придется вручную вводить капчу (это буквы и цифры с картинки). Жаль нельзя антикапчу «встроить» в браузер, было бы вообще круто. 🙂
Экспорт
Дальше экспортируем наш проект в Кей Коллекторе в обычную таблицу в Excel. Конечно, в идеале можно все ключевые слова вместить в один документ, просто по вкладкам внизу разбить на группы, категории. Но в моем случае проект относительно очень большой (интернет-магазин все-таки), у меня куча разных категорий и чтобы не запутаться клиенту, ну и будущему оптимизатору сайта (а может это буду я? 🙂 ) я разбиваю весь проект на несколько разных файлов. То есть у меня будут: коляски.xlsx, автокресла.xslx и прочее.
Перед экспортом я рекомендую немного изменить настройки Key Collector. Формат экспорта поставьте XLSX (удобнее работать в Excel), также там же внизу можете сразу отметить только те столбцы, которые вам интересны для экспорта. В моем случае это ключевое слово, его точная частотность и KEI 1, то есть конкурентность.
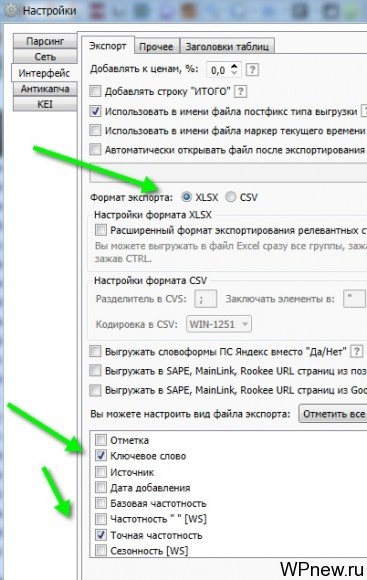
Чтобы экспортировать, просто нажмите на соответствующую кнопку. Если вам нужно выгрузить все группы сразу, то удерживайте кнопку Shift перед нажатием на кнопку экспорта:
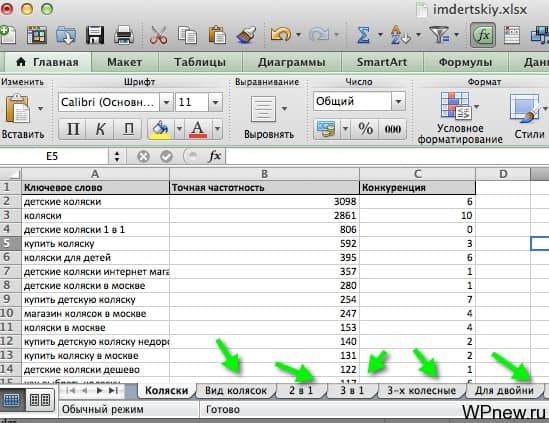
То есть получается примерно такая картина:
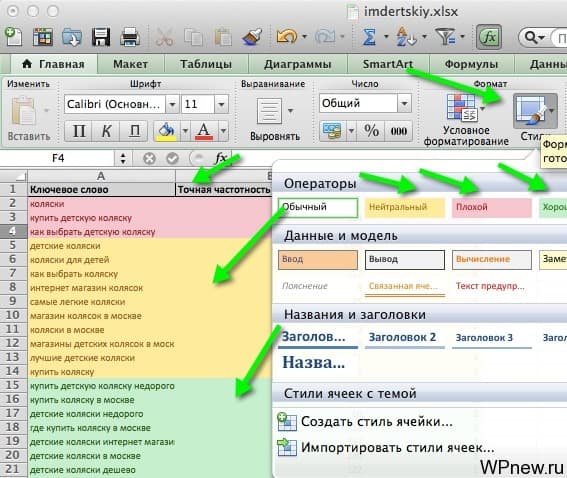
Для наибольшей наглядности можно сначала отсортировать таблицу по значению «Конкуренция» и придать соответствующие стили:
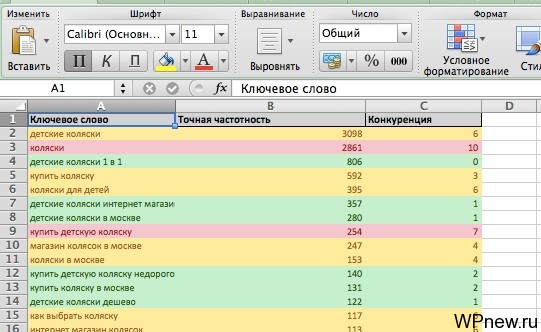
А уже потом обратно отсортировать по показателю «Точная частотность» и получится примерно такая картина:
И таких куча вкладок. В сумме у меня получилась не одна тысяча запросов. Примерно такой вариант семантического ядра я отправляю клиенту.
Итог
Как видите такие программы, как Key Collector очень сильно облегчают работу, а главное дают положительный результат для будущего продвижения сайта, если же конечно пользоваться правильно. Если же проект довольно большой, как в моем случае, крайне сильно облегчает работу База Пастухова.
Если кому-то что-то не понятно, а может кто-то предпочитает в видеоформате рассказанное мною в последних уроках, не огорчайтесь. Все это более наглядно и подробно, а также много чего другого интересного вас ждет от меня уже скоро. Ждем вторую половину октября.
Теперь вы готовы пройти следующий урок: «Что делать с семантическим ядром сайта?»




Способ с удалением пустышек я тоже использую, если по Центру частотность <20 — удаляю это ключевое слово.
Почему? как это влияет?
Такой вопрос — будет ли разница в показателе частотности «!» при сборе через разные регионах Директа? Например одинаковый запрос в Москве и Белоруси?
Да, конечно.
Мощно!
Спасибо! 🙂
Чую я нужно денежку на коллектор собирать 🙂
Артем, давно уже пора 🙂
Петр а ты что ссылки перестал продавать? Не покупают или заботишься о трасте блога?
Уменьшаю заспамленность сайта ненужными внешними ссылками. 🙂