
Приветствую, ребята! Совсем недавно я рассказывал вам про то, как удалить ненужные страницы с индекса Яндекса и Google. Для поиска «соплей» (мусорных страниц) я показывал, что использую ручной режим. Но в комментариях к тому урок один замечательный человек Антон поделился с тем, как можно облегчить поиск подобных страниц с помощью программы ComparseR:
Я сразу же попробовал ее на деле и остался под впечатлением! Действительно очень крутая штука! ComparseR позволяет изучит индекс сайта.
Программа ComparseR для разбора индексации сайта
Функции и особенности ComparseR
Основное предназначение программы ComparseR — это узнать, какие страницы существуют на сайте, какие из них в индексе, какие нет. Либо наоборот, какие ненужные страницы с Вашего сайта попали в индекс.
Особенности ComparseR:
- Умеет сканировать страницы в индексе Google и Яндекс для дальнейшей работы с ними.
- Возможность автоматического удаления (пакетно) ненужных страниц с индекса Яндекса и Google (не нужно залезать в панели вебмастеров).
- Краулер для подробной информации по страницам сайта (коды ответа сервера, title, description, количество заголовков и пр. информация, подробности ниже).
- Сравнение реально существующих страниц сайта с поисковой выдачей. С легкостью можно найти страницы, которые, к примеру, отдают 404 ошибку, но находятся в индексе. Там же в программе удалить все это пакетно. Масса возможностей.
- Возможность работы с сервисами антикапчи, прокси, XML яндекса
- Сбор статистики, удобное отображение проблем с сайтов (выделение красным).
- Возможность выгрузки структуры сайта.
- Создание sitemap.xml, особенно актуально, если движок не WordPress.
- Поиск исходящих ссылок с сайта.
- Сканирование изображений на сайте, значение их title, alt и пр.
- И многое-многое другое.
Программа ComparseR интуитивно понятная, выглядит вот так:
Как удалить ненужные страницы из индекса
Допустим, мне понадобилось удалить страницы из индекса Google. Они случайно попали туда в индекс и я хочу избавить от них.
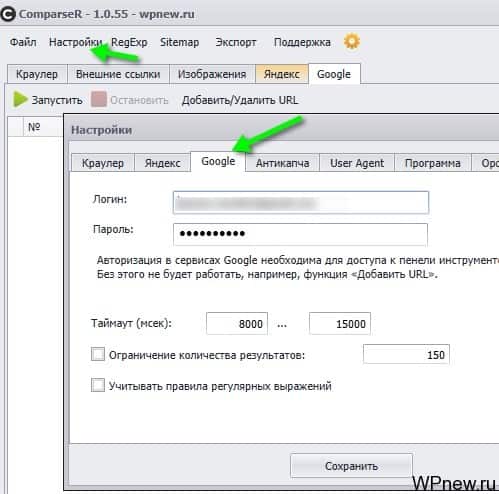
- Первым делом в настройках указываем логин и пароль от аккаунта Google, указываем тот аккаунт, на который привязан наш сайт, либо тот у которого имеется полный доступ (внимание, ограниченный доступ не подходит):

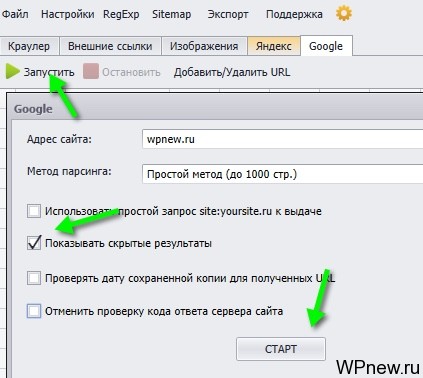
- Заходим во вкладку Google:

- Нажимаем кнопку «Запустить». Вбиваем адрес сайта, ставим галочку «Показывать скрытые результаты»:

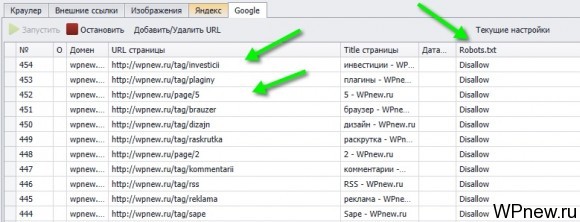
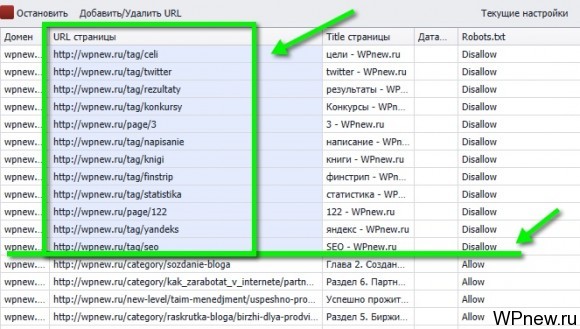
- Ждем немного. Теперь первым делом можно удалить те страницы из индекса, которые вы запретили индексировать в robots.txt (согласитесь, если Вы запретили индексировать в нем, то страница вам не нужна в индексе). Для этого сортируем по столбцу Robots.txt, чтобы шли страницы со значением Disallow, там же увидим ненужные страницы в индексе (у меня это страницы с тегами, страницы листинга с содержанием page и пр.):

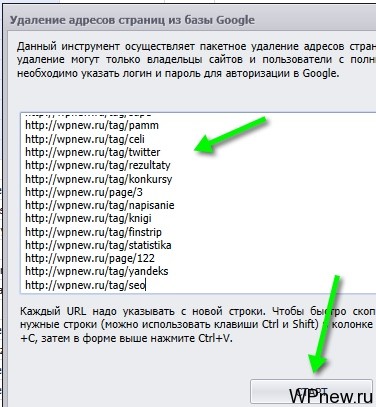
- Выделяем все эти URL, нажимаем CTRL+C:

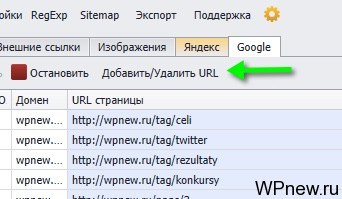
- Нажимаем на кнопку «Добавить/Удалить URL»:

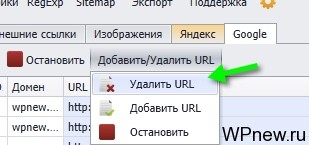
- Там выбираем «Удалить»:

- В появившемся окне нажимаем CTRL+V и нажимаем «Старт»:

- Вот и все! Эти страницы скоро выпадут из индекса. Можете зайти в Google Search Console и увидеть там список URL, которые поставлены на удаление:

- Согласитесь, это очень круто!!! Экономит уйму времени, не нужно лазить вручную и искать мусор в индексе, а потом по-одному вбивать их на удаление. Крутая программа.


Также можно отсортировать по колонке «Ответ сервера» и удалить страницы, которые отдают 404 ошибку и попали в индекс, если таковые имеются. Ну или вы видите, что ненужные страницы попали в индекс, запрещаете его индексирование сначала с помощью robots.txt, к примеру, потом ставите на удаление уже в этой программе.
Яндекс
С Яндексом абсолютно все точно также, вы сможете также легко посмотреть, какие страницы у Вас попали в индекс, при необходимости дописать правило в Robots.txt и воспользоваться «Удалить URL» в ComparseR уже во вкладке «Яндекс». Аналогично также можно добавить страницы в «аддурилку», если это вам нужно.
Краулер
В программе еще есть так называемый «Краулер». Кто работал с программами типа Netpeak Spider, Xenu и пр. поймут что это. Идет сканирование страниц Вашего сайта и вы получаете информацию по ним (кликните, чтобы увеличить):
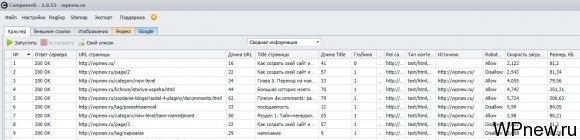
Тут доступна следующая информация:
- Порядковый номер.
- Ответ сервера.
- URL страницы.
- Длина URL
- Title страницы.
- Глубина.
- Meta robots.
- Rel canonical.
- Тип контента.
- Источник.
- Robots.txt (allow/disallow).
- Скорость загрузки.
- Размер страницы (в Kb).
- Description.
- Длина description.
- Количество заголовков h1.
- Сам заголовок.
- Длина h1.
- Количество заголовков, непосредственно сам заголовок и длина h2, h3, h4, h5, h6.
Как видите много нужной информации можно выдернуть.
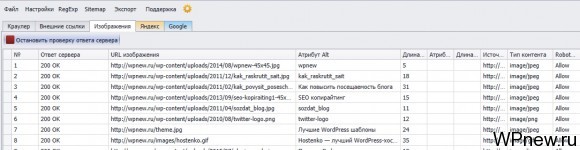
Также при краулинге, можно поставить галочки напротив «Собирать данные о внешних ссылках» и «Собирать данных об изображениях» и станут доступными вкладка «Изображения». Там можно увидеть тайтлы, alt тексты картинок и др. информацию по ним.
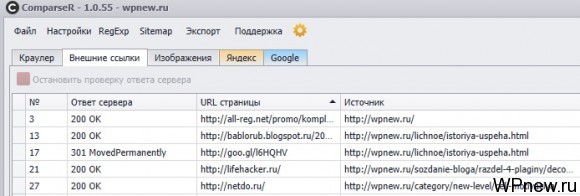
А во вкладке «Внешние ссылки» можно увидеть с какого URL вашего сайта и куда идут ссылки:
Статистика и структура
У программы есть замечательный блок «Статистика и структура» в правой части:
Наведя мышкой на нее, можно увидеть вот такой блок:
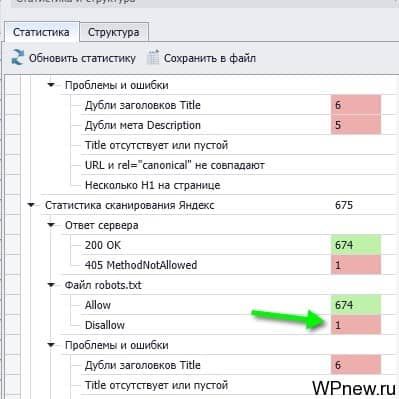
Очень удобно! Например, кликнув в разделе «Файл robots.txt» disallow: 1 (см. на стрелку выше), можно сразу увидеть, какие страницы попали в индекс Яндекса, несмотря на то, что они запрещены к индексированию в robots.txt:
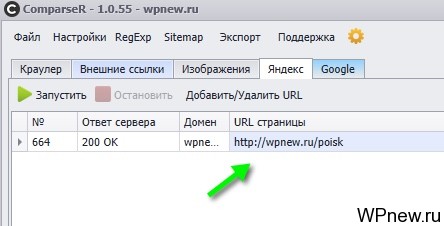
И эту страницу снова можно с легкостью удалить через кнопку «Добавить/Удалить URL».
Очень много информации и фильтров во вкладке «Статистика»: можно посмотреть какие страницы попали в индексе, какие нет, где присутствуют дубли в метатегах и другое. Удобно.
Структура сайта
Там же во вкладке «Статистика и структура» можно посмотреть структуру сайта:
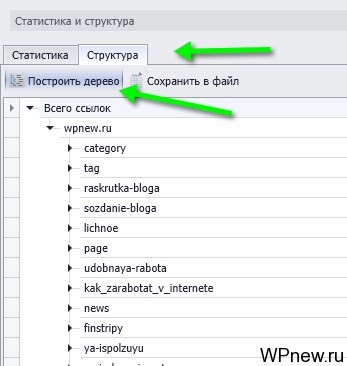
Таким образом можно спарсить структуру какого-нибудь сайта, который понравился очень и отличается хорошо продуманной структурой. Какие-то хорошие идеи перенять себе. Либо посмотреть на структуру своего сайта, чтобы узнать, как видят его поисковики. При необходимости можно сохранить все в файл.
Также с легкостью вы можете создать карту сайта sitemap.xml. Для WordPress сайтов — это очень просто реализовать с помощью плагинов, к примеру WordPress SEO. Если же движок самописный или какой-то сложный, можно просто снова воспользоваться программой ComparseR:
Вывод
Не знаю как вам, но мне программа мне очень понравилось. Постоянно приходилось вручную ковыряться в индексе и смотреть: какие же ненужные страницы попали в индекс Яндекса или Google. Теперь очень наглядная картина перед моими глазами, причем довольно удобная и понятная. И не нужно «залипать» в Яндексе для проведения аудитов. Очень крутая вещь. Аналогично легко проверить какие страницы НЕ попали в индекс.
Да, программа платная, но у нее есть демо-режим для полного ознакомления, работать можно со 150 страницами сайта. И больше никаких ограничений. Если у вас еще сайт не очень большой, то этого вполне достаточно.
А как вы анализируете поисковой индекс? Вручную или с помощью каких-то специальных программ/сервисов?




C программой уже можно решиться поубирать «сопли». Ручной же способ для молодых блогов.
Да даже с молодыми очень просто тут все. Причем можно и бесплатно сделать, не нужно «тыкаться».
Привет! При скачивании демки Хром выдал предупреждение, что файлы могут нанести вред компу, это не страшно? )
Не страшно, это обычное стандартное предупреждение.
«Сопли» (supplemental) — страницы в дополнительном индексе гугла. И это вовсе не мусорные (технические) страницы. Учите матчасть.
Я все равно не люблю лишнее, даже в дополнительном индексе.
И вообще, удалось найти ненужные страницы и в основном индексе Google, ну и в Яндексе тоже.
Да, но иногда страниц в индексе оооочень много, а у поисковиков есть некотрый лимит на кол-во страниц сайта в выдаче. Поэтому крупные проекты делают на поддоменах.
Коммент не по теме. Сейчас у тебя на блоге Петя вижу фото с комментом от Антона. И понимаю, что я его уже видел сегодня но к тебе точно не заходил. Оказывается просто получил сегодня рассылку от ЧекТраст, и зашел на их сайт. У них там есть «Что говорят о сервисе специалисты» и 3 отзыва. Один из них и есть Антон Шабан с такой же фоткой)) А я сижу голову ломаю )
Офигеть так совпадение! Да, довольно необычно, да и память у тебя хорошая. 🙂
Было дело, мой отзыв) Чектраст тоже хорошая программа.
Полезный материал, сразу же в закладки добавил, на выходных буду изучать! Спасибо, Пётр.
Спасибо. Самое интересное, что в демо-режиме можно очень много чего сделать, то есть абсолютно бесплатно.
Тоже Яндекс проиндексировал закрытый от индексации poisk, но при попытке удалить, вот что прога выдала:
vysokoff.ru/poisk/ — Нет оснований для удаления
Но а в целом, программа очень крутая!
Значит нет оснований, это ответ Яндекса, а не программы.
А Яндекс там не приписал, что для удаления должно быть или в robots.txt стоять запрет, или перенаправление в .htaccess Можно добавить, а когда из поиска удалится, удалить и из этих документов. Я так делала